08 Oct 2018
This weekend has been 2/3 good for radio.
Saturday I went out to Queen's Park to throw a water bottle over a
tree branch, haul up a dipole, and see what I could drum up.

A couple of weeks ago I got a longer coax cable (50 feet, instead of
16 feet), so I was able to get the dipole up a little higher than
usual. I'm not sure if that made the difference, or if was just bands
opening up, but what a difference on 20m! The Reverse Beacon Network
was showing me reaching clear across the continent:
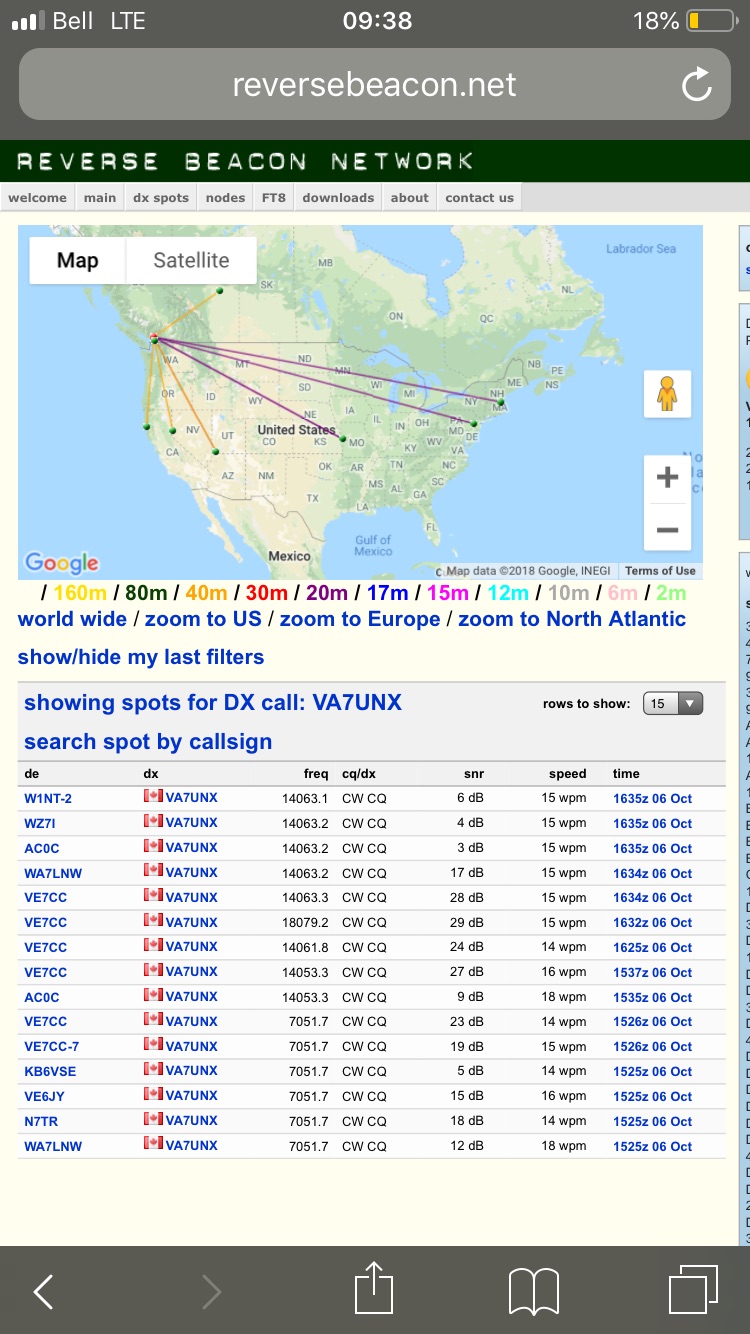
One of those stations, W1NT, is in Massachusetts -- over 3900km away!
Not only that, I was able to leverage that and actually make a CW
QSO. With only 15 watts, and me calling CQ, I had a nice chat
with Gary, AB0BM, in Cherokee, Iowa. I got a report of 559 --
not bad at all!
Sunday I was at my inlaws for Thanksgiving. My father-in-law enjoys
experimenting as much as I do, so he has put together a vertical
made of stainless steel pipe he just happens to have lying around
his garage. After laying out a bunch of radials on the ground, we
gave it a try...and got nowhere on 20m: no spots, and we couldn't
see our signal on any of the receivers we tried on sdr.hu. I
couldn't figure out what was going on, since the length (18 feet)
was about right for a 1/4 wave vertical. After we added another 7ft
length, though, everything changed: the RBN showed me again reaching
clear across the continent on 15W, and an SDR in New York State
picked us up clearly -- 3856 km!
As for QSOs, this time it was a little closer to home: VE7UBC, the
UBC Amateur Radio Society. Only 18 km away, but still good to
get one in.
Today, I went back out to Queen's Park. Luck wasn't good: I forgot
the coax (and ran back home to get it), got the water bottle halyard
stuck in a tree and had to cut the rope, made a replacement with a
bundle of sticks that didn't go nearly so well, and had nearly no
luck on 20m at all...no spots or anything, until suddenly it
opened up a bit: AC0C in Missouri and WB6BEE in Colorado spotted
me. Couldn't turn it into a QSO though.
Fell back to 40m where it was noisy as anything -- not sure what was
going on. Heard lots of folks showing up for the Novice Rig Night,
but couldn't manage to convert any of them. Dang!
Tags:
hamradio
qrp
03 Oct 2018
Last week I was incredibly privileged to attend the Open Source
Cubesat Workshop, held at the European Space Agency Space
Astronomy Centre in Madrid. I was there as a volunteer for Phase
4 Ground, an open source amateur radio project, along with project
leader Michelle Thompson and open-source figurehead (and, with
Michelle, founder of the Open Research Institute) Bruce Perens.
The conference took place over two days. Doesn't seem like much time,
does it? But there is a LOT to tell about the conference. To hit the
highlights:
The conference organizers were incredibly warm and generous, and
made it clear that there's room for everyone in the open source
space community -- not just aerospace engineers. (There's hope for
me yet!)
Presenters covered a wide range of work: everything from fully open
source cubesat missions, to open source software libraries for
flight dynamics, to proposals for new (and larger) modular
satellite platforms. Attendees included everyone from
university students and researchers, to members of national space
agencies (often with open source projects to share), to
open source volunteers, to librarians and archivists intent on
preserving everyone's work.
Capacity building was a big theme. The Argentinian Club de
Robotica was there to present a ground-based cubesat designed
to teach design principles for real space missions, with the
goal of creating the capacity and desire in Argentina for a cubesat
mission of their own. Also on hand was Rakesh Prajapati from Nepal,
speaking about the Poquetcube mission his foundation is creating in
his country.
I participated in two workshops. The first focused on the role of
Python in space; the second on how (or even whether) to improve the
PC104 standard so often used in cubesats. Being a fly on the wall
for these discussions was fascinating, and gave me a better idea of
the strengths and limitations of the tools the community has. Did
everything get settled? Of course not! But it was illuminating to
see the difference in approach between hardware and software, where
the costs and benefits of customization can vary so much.
And as with any great conference, the hallway track was a delight.
Being able to discuss integration problems on cubesat missions from
the researchers involved was amazing; so was talking with someone
investigating whether AI can be integrated into cubesats; so was
hearing people from different open source projects meet for the
first time, and compare notes about generating community
involvement.
All in all, it was energizing to be around so many people with similar
interests. I'm hoping to be able to participate in some very
interesting projects, as well as re-dedicate time to participation
in others.
This has been sitting in my "Composing" queue long enough, so it's
time to send this out the door; impressions of Madrid (it's
beautiful!) will have to wait. My full notes (warning: infodump) can
be found on the Phase 4 Ground Github repository.
Tags:
cubesat
space
opensource
phase4ground
satnogs
oscw
11 Aug 2018
Memo to myself: If mpd keeps crashing, try removing the files in
/var/lib/mpd.
Tags:
01 Aug 2018
Today I had the chance to visit Kennedy Space Center at Cape
Canaveral. I was there with my family, plus Andy Seely (who guided us
there with his awesome wayfinding superpowers) and his two sons. It
was an amazing time, and I want to write this down while it's fresh in
my mind.
Side note: I don't have much in the way of pictures. There are lots
of pictures that are much better than anything I'll be able to take,
and I didn't want to be distracted from being there and really seeing
what was in front of me.
First up was looking at the Mercury, Gemini and Agena rockets. It was
incredible to see how small they were -- not just the capsules, but
the rockets themselves. The only rocket we'd seen previously was the
first successfully landed first stage of a Falcon 9, and these things
were (I think) well under its height. And the size of the Mercury and
Gemini capsules -- wow. I knew they were small, but this was just
incredible. (Unfortunately, I didn't think to pay much attention to
the Agena rocket -- it would have been interesting to look at it and
think about the various EVAs the Gemini astronauts did when around
it.)
Next up was the Atlantis Space Shuttle. It wasn't direct -- instead,
like a theme park ride, there was a lineup (though, since we were
there on a Wednesday, it was incredibly short), then a film, and then
the great unveiling. And man...I did not anticipate being awed by a
Shuttle, but I was. No offense to the shuttle; it's the Apollo
missions that really awe me, and going to see Atlantis was more in the
"Eh, we're here, why not?" category. But seeing it...WOW. It was
amazingly big, and the way they've got it displayed -- horizontal,
wings angled like it's banking in flight, cargo bay open -- really
shows that off. I was awestruck.
One cool thing: Andy and I talked to the docent, who was a retired
NASA employee. It turned out he had not only worked on certain
Shuttle subsystems (hydrogen tanks, IIRC) but had also been involved
in the canceled Resource Prospector mission, a rover that would
have gone to the moon to pave the way for ISRU. Once he figured out
we were space nerds that he could geek out in front of, he talked in
depth about the work he was doing, the pain of seeing the mission
cancelled, and some frank talk about SLS and commercial options. It
was fascinating. KSC has a "Lunch with an Astronaut" program...which
should thrill me to death, but for some reason does not. I'd
totally go for a "Take a Docent to Lunch" program though. (Still
don't understand this part of my brain; I think both could talk in
equally technical depth about their work, and I think both would be
fascinating.)
After that we went through the Shuttle Launch Experience; it was fun
for me, but my youngest son found it pretty scary, so that wasn't
good. (I think he's pretty much put off on the idea of ever going to
space now.) After that, lunch...and then...
...the Kennedy Space Center Bus Tour, which took us by the Vehicle
Assembly Building, Historic Launch Pad 39A, and some other launch pads
as well (39B, maybe? my memory is already gone.) This was
interesting, but seeing everything from such a distance made it hard
to get a sense of scale. I was disappointed that the SpaceX Falcon 9
for Merah Putih was not out...but now that I check the launch
calendar, I see that it has been delayed again 'til August 7th.
Boo.
The KSC bus tour drops you off at the Apollo/Saturn V center;
again, you have to go through a film (interesting), then sit in the
Firing Room (launch control for the Apollo missions) to watch another
film (mildly interesting) before you get to the meat of the center:
the Saturn V mounted on its side, where you can walk underneath it and
see just how freaking HUGE this thing is. It was jaw-dropping. This
was the awe I expected, and it in no way disappointed. Walking out
under the F1 engines was incredible...and only beat by walking the
length of the rocket to see the incredibly tiny (by comparison)
command module up at the very top.
And the only thing that beat that was a lunar module hanging from
the ceiling. It had been built for Apollo 15, but was replaced by a
newer module. It was amazing to see it, to see how simultaneously big
and tiny it was.
After that, we caught the bus back to the main visitor center. We
bought souvenirs, and drove off to return to Tampa. (Another side
note: Orlando traffic is truly shitty.)
So. What to say about all this?
Seeing these things is like going to church. I'm staunchly atheist,
but I'm pretty sure that the sense of awe and wonder and grandeur
and tearing up and wanting to cry is a decent approximation of what
a devout person feels approaching the holy.
At the same time, it's hard for me to not notice all the Wondrous!
Space! Music! that's playing everywhere. It is stirring! and
uplifting! and like eating an inspiration sundae every 15 minutes!
By which I mean it's cloying after a while!
I dropped a stupid amount of money at the souvenir shop, knowing
full well what I was doing and doing it anyway.
I tried hard not to be a full nerd, but it was hard not to cringe
every time something mentioned SLS launching in 2018, JWST launching
in 2019, the Asteroid Redirect Mission or the Journey to Mars. (If
you're not a space nerd: those are either optimistic schedules that
have been overtaken by events, or NASA goals that were given to them
by one administration and removed by another. And for the record, I
would LOVE it if all those things were to happen on time.)
There was a woman wearing a ULA hat and a Parker Space Probe
hat. I complimented her on both, and it turns out she's on the
integration team for the PSP, and was there with her family on a
tourist outing in the middle of her work. I shook her hand and
wished her the best of luck with the launch.
There is a lot of "Thank you for your service" aimed at military
service people in the US. This can extend to things like "...and
here's 10% off your next mattress purchase." This strikes me as a
bit over the top...but I still wanted to thank the NASA docent for
their service to, I guess, humanity.
I could totally see myself coming back and spending a few days
visiting this place alone. I felt the same way when I visited the
Grand Canyon.
I am extremely grateful to family and friends for coming along with
me. These things are neat, but like anything else they are not
everyone's cup of tea.
The bus tour is fun...but the videos they play on the bus are a way
of passing the time during what is a very long drive between
interesting things.
I'd love to see the VAB from the inside to get a better sense of scale.
The souvenir shop had prints of Apollo 11 pictures signed by Buzz
Aldrin for $1800 each. I was tempted.
A few weeks back, it looked like there was a good chance that 2
rockets would be lifting off around this time. That has not
happened. In a way, I'm grateful...this was already a long day, and
I think adding a launch to it would only have made it longer (or
pushed other stuff to a future visit.)
Tags:
space
nasa
geekdad
30 Jun 2018
My parents are visiting for a while. I've had a few days off work, so
I've been heading over to Queen's Park in the morning with my dad
to do some radio. The weather hasn't been great, so I've been trying
some spots near picnic benches so we at least have a place to sit.
And I got some QSOs!
First up on 40m was Alan, K7FD in Seal Rock, Oregon via CW on Thursday the 28th.
This was only my 2nd CW QSO, and I'm still having a hard time copying
it. Fortunately, I was able to record it and go back later to
transcribe; unfortunately, I referred to him by the wrong call sign
twice in the exchange. headdesk Fortunately he seemed to have a good
sense of humour about it. My dad took this picture:

Second on 20m was Steve, N7MZP in Sand Point, Idaho via SSB (!) today.
Eli accompanied me and Dad to the park, and was happy I'd managed a
contact:

I answered his CQ, and was quite surprised to hear him come back to me
-- I have not had great luck with SSB so far (which isn't surprising,
given that I'm only running 15W). The report I got was 52 up to 54,
with some fading that we both noticed.
For all these contacts, I've been using a dipole or inverted vee,
rather than the end-fed random wire with EARCHI matcher. Last weekend
I found the Coquitlam club's Field Day setup, and one of the
folks I talked to convince me to give dipoles a try. I think I'm
noticing a lot less noise, but haven't yet done a side-by-side
comparison.
Tags:
hamradio
qrp
23 Jun 2018
Let's see if this still works....yep, apparently, it does.
Updates:
Got my ham license in March -- my callsign is VA7UNX. I got Basic
with Honours, which in Canada means you get to use the HF bands.
I've picked up a used Elecraft K2, and have been mainly working QRP
out of parks and trying to figure out antenas. I've made a handful
of contacts on SSB to Oregon and Washington during the 7QP
contest, and just last week made my first CW QSO to N6RNP in
Chico, California (1050km!).
I went to Hamvention in Dayton^WXenia, OH and met folks from the
SatNOGS and Phase 4 Ground projects. That was excellent.
At Hamvention I picked up an Arrow II antenna from the AMSAT folks,
plus a spare Baofeng (at $25, why the heck not?) and have been
trying to work satellites. No luck yet, but efforts continue.
I'm going to be attending the Open Source Cubesat Workshop in
Madrid this September, kinda-sorta as part of the Phase 4 Ground
project. This blows my mind.
I've put in an order for most of the parts for a SatNOGS rotator.
They're slowly trickling in, and hopefully I can get something
working by the fall.
There will be a trip to Tampa this summer to visit my good friend
Andy Seely.
Now back to cleaning up the house in preparation for my parent's visit.
Tags:
space
hamradio
qrp
cubesat
27 Sep 2017
This week, $WORK has sent me to North Carolina for a week's worth of
training. The campus is on the edge (though not within) Research
Triangle Park, and as such it's right in the middle of Durham, Raleigh
and Chapel Hill. It's interesting around here.
When I first looked at the map, I figured I might walk from my hotel
to the campus; sure, it'd be an hour, but it's all beautiful forest.
Nope: it's forest, but it's highway here; there are no sidewalks to
speak of, no walking paths; everyone I've told this fantasy to has kind
of cocked their heads at me a little, like I've just earnestly
explained how I was really looking forward to seeing the talking
penguins of North Carolina. "Everyone drives here," said one woman.
"I mean, I like hiking, but I drive 40 minutes to get to the park."
Oh well, there's still lots to see. Like the signs that say you're
not allowed to carry a concealed weapon:
Or the beautiful lake, just 30 seconds walk away from the cafeteria:
The campus is weird this way; it's a strange mix of Office Space and a
beautiful setting that reminds me of UBC. There's a company souvenir
store right next to a sand park where you can play volleyball right
next to a big parking lot right next to some beautiful landscaping
right next to squirrels. I get the bends just turning my head.
Because there's nowhere to walk, the last couple of nights I've taken
a cab out to Chapel Hill, a university town (they're all university
towns) just down the road. I've had a chance to walk around a bit,
grab supper and a beer, and get a sense of what it's like. And it's
nice. There are trees everywhere; you can see the stars even from
downtown (try that in Los Angeles); there are lots of bars and
restaurants, but not so many that it doesn't feel like you could take
your kids there; the architecture is beautiful, and the beer is good
(even if it is from those jerks at Duke).
Tags:
22 Sep 2017
Let's see if I finish this.
The movie "Memento" sometimes feels far too close to home. If you
haven't seen it, the protagonist has amnesia; he has notes tattooed
all over his body as reminders of things he's learned, then forgotten
and relearned, and finally had to have written onto his skin to keep
in his head.

There are times when this feels like a frighteningly accurate
description of how my head works. I have blind spots: things I know
the answer to, but I forget until someone points them out to
me...whereupon I shake my head, remind myself to remember them, and
promptly forget them. They're facts that, remembered in time, let me
pull out of some steep dive into anger and frustration. More often,
they're things someone has to repeat to me, like being told "You've
had a stroke" as you stare up into the sunlight wondering how you got
down the sidewalk like this. And they're not new, at this point in my
young life.
It is a fine thing to be old enough to recognize your own
shortcomings. (Let's leave aside the question of whether that's
wisdom or just settling.) It is disheartening to realize you've been
through all this before, that the revelation came already and went,
and there is every reason to believe the footsteps you are following,
arcing ever so slightly to the side as they approach the horizon,
are your own.
Tags:
28 Dec 2016
Today I was out with the kids, and we came across a place selling
fresh-baked pretzels. "Mmm, those smell GOOD," said Eli. "Want to
try making some when we get home?" I asked. "Sure!" he said, sounding
surprised that such a thing was even possible. One quick check of
"More Food that Really Schmecks" later, and we were off to the races.







Tags:
geekdad
05 Dec 2016
LISA again! This is the fifth? (Washington, Baltimore, San Diego, San
Jose, Seattle, and now Boston) sixth! that I've been to. Saturday's
flight in was fairly uneventful, except a) it didn't bother my
sciatica too much, so yey and b) I forgot my coat on the plane, and it
doesn't look like Air Canada has a working system to take "Hey, did
you see a coat?" calls.
Fortunately I can count on the kindness of Andy Seely, who brought an
extra coat and loaned it to me. For his kindness I have given him a
"Taggart Transcontinental" t-shirt, and let him buy me supper. I'm
nothing if not generous.
Sunday I spent the entire day at the Google SRE tutorial, which was
very, very cool; a big part of it was an exercise to architect a
system that would read and join logfiles. It took a long time to wrap
my head around how everyone was thinking about this, but writing down
the moving parts made it all a lot clearer. In the end, my team's
proposal approximated the final example config presented by Google, so
that was good. Final sol'n, BTW, used 101 machines. The math all
worked out, but it still made my jaw drop. When I asked the
presenters about this, they grinned. "We've forgotten how to count
small," one of them said.
Today was spent in "Everything you ever wanted to know about operating
systems but were afraid to ask", aka "Caskey's Brain Dump". It was a
pretty awesome talk, covering everything from silicon through
filesystems. Well worth it; I'd love a recording of it, since the
slides simply don't do it justice.
Tags:
lisa
27 Nov 2016
For the last couple of months, I've been having? encountered?
enjoyed? sciatica. It has been oh so very fun, by which I mean not
very fun at all. The pain is ungood, of course, but the toll it has
sometimes taken on my mood has been worse. I'm generally pretty
easy-going, but it has been hard to stay happy when random pains come
shooting out of nowhere. (I'm seeing a physiotherapist and it's
getting better, but it is taking time.)
One side effect has been a generalized lack of patience. So, in short
order I have switched ISPs after a persistent billing error; stopped
hosting my website and mail at home; stopped trying to automate the
creation from scratch of my web and mail server ("fuckit, just
rsync"); and bought a new laptop when my old once began, once more, to
freeze whenever I closed the lid.
Next week I fly to Boston to go to LISA. It'll be good to see folks
again, but I'm kind of dreading the flight. I booked everything long
before this came up. It's getting better, but I'm still going to see
if I can upgrade to premium super econoplus with extra morphine.
In other news, I have finally started reading "A Game of Thrones", and
I find myself close to enthralled. It's well-written and enjoyable,
and if it doesn't strike as close to my heart as James S.A. Corey,
it's still getting me to pick it up and read it every day.
Tags:
19 Nov 2016
Docker refuses to start. My IPv6 tunnel has started working again
after it refused to do so. I have had it with home system
administration. I have better things to do with my time.
Tags:
11 Nov 2016
Holy crap, Glenn Beck is a reasonable man:
If you voted for Hillary Clinton this week, you likely feel
despondent, confused and unable to reconcile how the country elected
Donald J. Trump. “Don’t people see how dangerous this man is?”
Clinton supporters asked. “Our entire way of life is at stake.”
I get it. I opposed Mr. Trump, too. But this is how nearly half the
country felt eight years ago. It does not matter if we do not
understand one another’s feelings. What matters is that we at least
hear them.
How do we stop the cycle?
Tuesday night, as it became apparent that Mr. Trump would win, I saw
myself as others may see me. Pundits were beside themselves talking
about sexism, “whitelash” and bigotry. I read three articles
comparing him to Hitler. I understand what they meant. But just as
President Obama was not a Manchurian candidate, Mr. Trump is not
Hitler. The seeds of 1933 may have been planted, but they can grow
only through our hate and divisiveness.
I don’t question your right and reasons to feel fear. But don’t fear
Donald Trump the way I feared Barack Obama. I read a perfect
election summation: The people who were against Mr. Trump took him
literally but not seriously. His supporters took him seriously but
not literally. It is the same pattern of 2000 and 2008. We heard
President Obama was coming for our church and our guns. We were
mocked. We thought those who laughed were lying or stupid. Yet, I
still go to church, sometimes with a gun.
Tags:
politics
10 Nov 2016
Well, that happened. Tuesday night I went to bed hoping for better
news. I woke up at 2.30am, unable to sleep; after a while I gave up
and came down. Still no good news. President Trump it is, help us
all.
But. This morning there was an ISS flyover, and a rare semi-clear sky
to see it. So I fired up the ISS HDD viewer on my laptop, went
outside, and watched the sun rise from the ISS while I watched it fly
overhead, a wonder heading for the dawn.
Tags:
politics
space
05 Oct 2016
Today's title from the subject line of some spam I just got. ("a
spam"? "a spammy email"? just "spam"?)
Mystery flu-like illness continues, or at least its fallout; I've
had lower back pain for the last ~ 4 weeks. Doctor says removing
spine is "not an option" but I've done some Googling and
$WORK continues apace. After taking a week of Python training, we're
using Go for a new tool we're building. Haven't got a good sense
for what it's like just yet, but so far I don't seem to be making a
mess of things.
Tried out drone.io at $WORK yesterday and holy god, is it
good. Auth with our internal Github, then activate repos, and boom!
it runs tests on every new commit on any branch, watches for PRs,
the whole nine yards. When I think of the amount of work we had to
do to get Jenkins to do this, it's insane. Plus the whole
run-as-a-Docker-container,
fire-up-sibling-docker-containers-for-tests thing is very, very
impressive.
Sportsball has started up again with a vengeance: practices on
Monday and Wednesday, games on Fridays and Saturdays. Somebody stop
this merry-go-round!
I've registered for LISA 16, woot! This will be my fifth --
wait, sixth? -- LISA, ten years after my first time attending.
Not sure who's gonna be the theme band this year -- I've done New
Pornographers, Josh Rouse, Soul Coughing and Sloan. And since he's
co-chair this year, it seems like a good time to pull out that
picture of Matt Simmons (@standaloneSA) as a PHP dev:

Tags:
spam
geekdad
lisa
python
golang
drone
02 Oct 2016
I have spent this weekend debugging shit on my home server: I've
managed to break my IPv6 tunnel and Docker networking, and for some
reason /etc/resolv.conf was emptied I don't even know why. Last
weekend I spent far too much time debugging problems with DKIM and SPF
and breaking my wife's email, and that was with only one domain; I've
still got another to go through. I am thoroughly sick and tired of
it.
I have always thought it important to run your own server (buy me a
beer some time to get the reasons), but I am done. Done, I say. I am
ready, at this point, to throw money at someone or something to just
make this go away. I still want my own SSH server at home -- that's
too much to give up -- and I still like checking my mail with Mutt.
But web hosting, docker networking, metrics, monitoring, DNS, backups,
calendaring -- gahhhhhhhhhhhhhh.
Probably, I am just going to put all this away for now, leave the
unpaid sysadmin work for another time.
Tags:
wellnotreally
26 Sep 2016
The recent Lawfare Podcast episode "Disrupting ISIS Recruitment
Online" makes fascinating listening. It's a recording of a panel
discussion consisting of two Google-affiliated companies that do
targeted advertising aimed at, well, disrupting ISIS online
recruitment, and the US Undersecretary of State for Public Diplomacy
and Public Affairs.
It is, at first listen, profoundly weird to hear the jargon of online
advertising applied to propaganda. (It's propaganda I agree with, but
propaganda nonetheless.) But then I realized where I'd come across
the idea before: Robert A. Heinlein's "If This Goes On --".
Here's a quote:
'I'm in the Psych & Propaganda Bureau,' he told me, 'under Colonel
Novak. Just now I'm writing a series of oh-so-respectful articles
about the private life of the Prophet and his acolytes and attending
priests, how many servants they have, how much it costs to run the
Palace, all about the fancy ceremonies and rituals, and such
junk. All of it perfectly true, of course, and told with unctuous
approval. But I lay it on a shade too thick. The emphasis is on the
jewels and the solid gold trappings and how much it all costs, and
keep telling the yokels what a privilege it is for them to be
permitted to pay for such frippery and how flattered they should
feel that God's representative on earth lets them take care of him.'
'I guess I don't get it,' I said, frowning. 'People like that
circusy stuff. Look at the way the tourists to New Jerusalem
scramble for tickets to a Temple ceremony.'
'Sure, sure-but we don't peddle this stuff to people on a holiday to
New Jerusalem; we syndicate it to little local papers in poor
farming communities in the Mississippi Valley, and in the Deep
South, and in the back country of New England. That is to say, we
spread it among some of the poorest and most puritanical elements of
the population, people who are emotionally convinced that poverty
and virtue are the same thing. It grates on their nerves; in time it
should soften them up and make doubters of them.'
'Do you seriously expect to start a rebellion with picayune stuff
like that?'
'It's not picayune stuff, because it acts directly on their
emotions, below the logical level. You can sway a thousand men by
appealing to their prejudices quicker than you can convince one man
by logic.. You can sway a thousand men by appealing to their
prejudices quicker than you can convince one man by logic. It
doesn't have to be a prejudice about an important matter
either. Johnnie, you savvy how to use connotation indices, don't
you?'
'Well, yes and no. I know what they are; they are supposed to
measure the emotional effects of words.'
'That's true, as far as it goes. But the index of a word isn't fixed
like the twelve inches in a foot; it is a complex variable function
depending on context, age and sex and occupation of the listener,
the locale and a dozen other things. An index is a particular
solution of the variable that tells you whether a particular word is
used in a particular fashion to a particular reader or type of
reader will affect that person favorably, unfavorably, or simply
leave him cold. Given proper measurements of the group addressed it
can be as mathematically exact as any branch of engineering. We
never have all the data we need so it remains an art-but a very
precise art, especially as we employ "feedback" through field
sampling. Each article I do is a little more annoying than the
last-and the reader never knows why.'
I'll leave my ambivalence about Lawfare for another day. For now:
the podcast makes fascinating listening, and if you haven't read "If
This Goes On--", I highly recommend it.
Tags:
politics
15 Sep 2016
This week I've been taking Python3 training at work: 4 days of
staying at home and concentrating on Python. The result? 4 days to
work on Python, sharpening my skills, and that's a good thing. The
lecture was not that hot, but what was useful was having the
exercises in front of me, waiting to be done and no distractions to
keep me from them. And after all that, the biggest difference I
notice between Python 2.7 and Python 3 is print "foo" vs
print("foo"). (Which shows you how much Python I know. But
still.) I finished the exercises a few hours early, so I spent the
time trying to solve the coding challenge we give new people at
OpenDNS. (I didn't get that one; instead, I got the "this machine
is borked in 12 different ways, please solve it" challenge.) This
has been a wonderful way to stretch my brain, and work on something
very very different from what I do every day. I wish work had the
same sort of course for Ruby and Go.
Have I mentioned that I've come to love Bandcamp? Lots of
excellent music, and I keep finding lots of excellent music. I
mean, really really excellent music.
Like Hairy Hands.
Or Mars, Etc.
Or Snail Mail.
Also on the music front, one really excellent station I've found is
Popadelica.
But back to Python: despite the click bait title,
O'Reilly's "20 Python Libraries You Aren't Using But Should" is wonderfully informative for this Python n00b.
I loved showing this video to my kids, demonstrating how
bacteria evolve.
Set up a Tor node last week for the cause.
Tags:
randomupdates
music
programming
geekdad
11 Sep 2016
There are three people I know that are, or have been, close to death
in the last year. One had a double mastectomy last fall when she
discovered she had breast cancer. Another fell down confused one day
earlier this year and discovered she had stage 4 brain cancer. And
the third got taken to hospital a few weeks ago because, it turns out,
she's alcoholic and has pretty much destroyed her liver.
One is getting better; her hair is growing out after chemo and
radiation, she's playing music again (she's incredibly talented), and
seems to be nearly endlessly positive (at least around me). Another
is taking things day by day, travelling when she can, trying to eat
(her sense of taste has been destroyed by the radiation treatment),
hanging out with her grandchildren. And the third has been in detox
for a few weeks now, and has a long road in front of her if she's
lucky.
One was a close friend, then we lost touch, and now we make a point of
seeing each other regularly; it's not as often as I'd like because we
each have our own commitments, but it's wonderful to talk to her again
after so long because she's funny and talented and just a righteous
pleasure to be around. Another lives far away, and for a long time
has been someone I knew about rather than knew; she's a good person,
but our lives are separate, joined only by the people we have in
common. And the third was always a wonderful, funny person to talk to
at the social occasions we ended up at together, and I loved her
writing when she kept a blog, but I could in no way say I knew her.
One my wife and I have been able to help, at least in a material
way. Another, my wife and I have helped someone else be able to travel
to see her. And the third...well, the whole problem has only just
emerged, and we have no idea what to do, or what will help, or the
prospects of her being around long enough to help.
I've come to learn the way I react to things like this: shock and
numbness for an hour or two, then being surprised when I burst into
tears, then long weeks of worrying. I've begun to be wary of hearing
about someone I haven't thought of in a while, because this is when
things and people fall apart and some days it feels like the news is
never good. And I've started to think about why we go to funerals,
and the way grief and mourning and remembering are built somehow into
our DNA, our shared heritage with all the other animals that cherish
and love and mourn and, in their turn, die.
Tags:
wellfuck
06 Aug 2016
Tonight I went out to the local park with the scope. I had a bit
better list than last time and stuck to it, and ad the end of the
night I was able to shut down & be home in 10 minutes. Not bad at
all.
So: Quick look at Saturn to start with, before it set beneath the
trees. Very nice.
Managed to split Double-Double in Lyra, but I had to use the 6mm
Radian to do it. South pair easier to split than the north pair.
Followed ISS with the scope (17mm, 71x) and man, that was neat.
Omicron Draco: double star, yellow and green/blue. Not my thing,
double stars, but I do like the ones that resemble Earth & the sun
(blue + yellow). Colours on this one were more subtle, though.
M56: Faint. No sign of resolution.
NGC 6939: OC in Cepheus. Took a while to track this down, as it was
a lot fainter than I expected. Got a sketch.
NGC 6543, the Cats-Eye Nebula: Saw this straight off, an obviously
non-stellar object. Faint blue. Neat.
M92: Aw! Looks like photo of a spiral galaxy. Liked it better
than M13, which I looked at next.
NGC 6229: GC in Hercules. Faint like a Q-Tip, and no resulution at
all.
NGC 6709: OC in Lyra. Nice! Big, sparse, and kind of reminds m of
a fish shape. Mentioned in "Annals of the Deep Sky", which I'm enjoying.
Packed it in at 12.15am. Overall, a lot better than last time.
Tags:
astronomy